 Columns
Columns
Columns
ColumnsPete handles just a few small issues this month. Like how to write Japanese filenames, avoid memory leaks, and preserve binary compatibility across releases.
To ask Pete a question about C or C++, send e-mail to petebecker@acm.org, use subject line: Questions and Answers, or write to Pete Becker, C/C++ Users Journal, 1601 W. 23rd St., Ste. 200, Lawrence, KS 66046.
Q
Why are wide characters not supported in C and C++ file names? As far as I can see, most of the C and C++ runtime library functions and classes come in both wide and narrow flavors regarding characters, with class type_info, class exception, and the file stuff as exceptions. I can understand that type_info's name function returns a char pointer, since that name is restricted to the character set allowed for C/C++ source code. For exceptions, I can understand it because of the (probable) extra memory requirements for allocating either an extra string or converting a string. But why is there no standard way of referencing file names in an extended character-set?
— Rune Huseby
A
I suspect it's mostly historical: at the time that the C standard was being developed the primary technique for handling international character sets was through multibyte characters, not wide characters. That's carried through in both of your examples: type_info::name and exception::what both return a const char *. In both cases, the C++ Working Paper says that the function returns a null-terminated byte string which "can be a multibyte string suitable for conversion to a wstring." This lets vendors use international character sets without having to provide a separate function that returns a pointer to wchar_t.
In the past few years wide characters have come into their own, at least on the programmer's end of the code, but there still aren't very many operating systems that support wide characters in file names. For example, Windows 95 accepts wide characters in file names, but assumes that any such names are simply wide character versions of ordinary ASCII text; the operating system itself uses ASCII to represent file names. This makes using wide characters in file names rather pointless. Until there's significant support in operating systems for wide characters, there's not much to be gained by providing a wide character interface to them.
Finally, it's not clear that wide character support in itself is the best way to go. If you look carefully at the new iostream specification or at the string specification you'll see that they don't support just wide and narrow flavors of characters, but are actually templates that can be used with fairly arbitrary character-like types. string is a typedef for basic_string<char>, and wstring is a typedef for basic_string<wchar_t>. These are the two template instances that will be used the most, but the language definition allows you to do a great deal more.
Personally, I think it's overdesign to provide a template where two classes would be sufficient, but I haven't done much work involving internationalization. I'm willing to defer to the folks who worked on these templates and accept their judgment that providing two classes, one for narrow chars and one for wide chars, isn't enough. The full range is necessary.
If it were to be consistent, rather than providing wchar_t versions of type_info::name and exception::what, the language would provide template versions of these member functions, capable of returning messages as arbitrary instances of basic_string. But making these template functions would be pretty tricky to implement, and I'm relieved that nobody gave it serious consideration.
I predict, though, that in five years or so, when more operating systems use Unicode to represent file names, you'll see more and more library extensions to handle additional character representations. As we gain more experience with the problems involved in translating between character representations, and understand better how to solve those problems, our programming languages will provide more support for using more sophisticated character representations in broader contexts, including using them for file names. Maybe we'll see that in the next revision of the C++ standard.
Q
My question is a simple yet stupid one, because I have yet to get used to using the man pages to actually find the answer, and I am also new to C programming. I just recently switched from Windows 95 to Linux Slackware 3.0, and I am trying to find out what functions exist on clearing the screen. Thanks.
— Christopher Aaron Baumbauer
A
Take a look at the C FAQ, question 19.4. The C FAQ is available online at
http://www.eskimo.com/~scs/C-faq/top.htmlThis should be a part of every C programmer's reference library. Many of the basic questions are answered here, in a practical, readable form.
The short answer is that there's no portable way to clear the screen in C. If you really need to do this, make a guess at the largest screen size that your program is likely to encounter, and write out enough newlines to clear a screen of that size. I've heard, though, that there are systems where this won't work.
Q
My question is about multidimensional arrays allocated and freed on the heap or free store. The code in Listing 1 is the recommended method found in the "Programmer's Guide" of some compilers.
I think I understand what is allocated and what gets freed. However, I have been using the syntax in Listing 2 for a long time and I believe it is working correctly. I can't explain exactly what gets allocated and freed, and I don't know how to prove or validate that the memory is deleted correctly.
My concern and question stems from the fact that the delete [] pchararray is exactly the syntax that would be used with a one dimensional array, such as
char *pchararray = new char[numelements];And being the same, how do the new C++ compilers know how to free the second dimension?
So my question is threefold: 1) Could you explain what is being allocated with the new operator and freed with the delete [] operator? 2) Is the memory correctly freed in a Windows 16- and 32-bit application compiled with Borland C++ 5.01 and MS Visual C++ 5.0? and 3) How can I validate or prove that the memory is freed correctly? I would really appreciate any help or guidance you could provide. Thanks.
— Tom Parke
A
Both of the approaches you mention will work. As to memory leaks, the simple answer is: as long as you have a delete for each successful new (see note [1] ) you won't have memory leaks. Although the invocation of delete looks the same in your code examples, the type of pchararray is different in each, and the compiler knows that it should handle the deletions differently.
Figuring out what these allocations do can be a very confusing subject, mostly because of the C rule that the name of an array decays frequently into a pointer to its first element [2] . This rule makes it hard to tell from the source code whether you're dealing with an actual array or a pointer. Let's look at your two examples in a little more detail to see what the differences between them are.
Let's begin with your second example. We can make it a bit clearer if we introduce a typedef rather than doing all of the declaration in one place:
typedef char Message[NUMCOLS]; Message *pchararray;The fact that Message is an aggregate type doesn't affect allocation or deletion:
pchararray = new Message[NUMROWS]; delete [] pchararray; // [3]As long as you match each invocation of new to an invocation of delete you won't have any memory leaks.
Note that after the invocation of new in the preceding code snippet pchararray is pointing to a two-dimensional array. That is, when your code invokes new, the compiler asks for a single block of memory that's large enough to hold all of the required data, and the compiler is responsible for figuring out where each Message begins and ends. The memory block looks something like this:
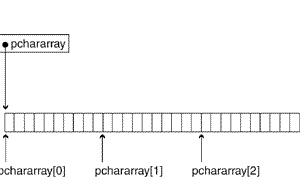
You can access the first message as pchararray[0], the second as pchararray[1], and so on. Within each of those messages you can access individual characters by using a second index. pchararray[0][2] is the third character of the first message.
The first example is more complicated. It declares pchararray to be a pointer to a pointer to char. The first allocation in the code creates an array of pointers to char, and stores the address of this newly allocated array in pchararray. The code then goes through a loop, allocating char arrays and storing their addresses in the array of pointers. Once you've done all that, the memory blocks look something like this:
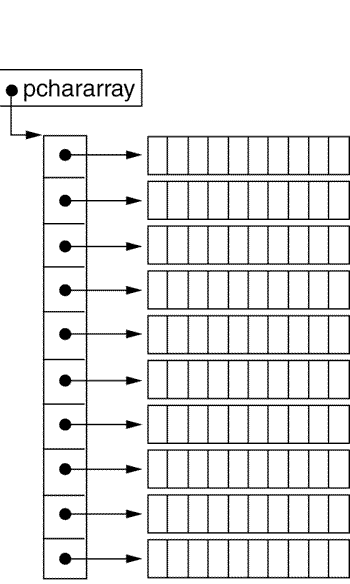
Despite the difference in memory layout from the previous example, you access these data objects in exactly the same way. pchararray[0] is the first message, pchararray[1] is the second, and so on; pchararray[0][2] is the third character of the first message.
Now, clearly, the actual code needed to figure out where pchararray[0][2] is located in memory depends on which of these schemes you use. It's the compiler's job to handle these differences and generate code that works correctly.
If you're using Borland's compiler you can check for memory leaks by compiling your code with CodeGuard. When you run it, CodeGuard detects any memory that you've allocated but haven't freed, as well as providing a number of other useful run-time checks. There are third-party products available to do this sort of thing with other compilers: Bounds Checker from NuMega provides an add-on for Visual C++, as well as a standalone product that works with other compilers; Purify is available for Unix compilers. There are several add-on libraries that will check your memory usage, but they don't provide the full range of other services like the products I've mentioned.
Some people write their own memory checkers. It's not very hard to write a replacement operator new and operator delete to keep track of the blocks that have been allocated but not freed. Regardless of how you do it, if you're a serious C or C++ programmer you should have some sort of tool to check memory usage.
Q
I'm working on a C++ DLL where versioning is important. New versions of the DLL will have to be sent out on a regular basis. In researching versioning, layout issues of C++ objects came up.
I've read various opinions about class layout, but they were usually concerned with the readability of the source code. Things like putting private members first because it is the default and you won't have to spend two seconds typing private. Others say put the private members first so class clients will see what's private. Then others say public first because that what class clients use.
With my DLL project someone finally said something that didn't have to do with readability. They said to put private last since the interface of the class probably won't be changing. Usually it's private members that get added and implementations that change in new versions. They went on to mention this will have less impact on the binary layout of the object. Is this true? Does the order of access specifiers and members influence how the compiler builds the object? I thought the parser collected all the class information and built the objects in a specific order at the binary level.
So even though my interface may not change, if I modify my class or implementation the binary-level changes can affect users of the DLL that were aware of the object's size. Since commercial software is updated all the time, how is this issue addressed?
In further reading I came across the statement that C++ was not designed with binary encapsulation in mind; that C++ was designed for source code encapsulation and recompilation. What I read also pointed out that object layout differs from compiler to compiler; that member alignment, vptr placement, virtual bases, and RTTI vary and cause incompatibilities for nontrivial classes. With component and distributed systems fast becoming the norm, is the ANSI committee considering adding more about compiler implementation?
Can you shed some light on any of these issues?
— Steve Barnette
A
Concerning components and distributed systems, the best I can do is to refer you to other sources of information. The problems involved in guaranteeing binary compatibility between objects are very tricky. You may have heard of the acronyms CORBA and COM — they're two of the competing standards for binary compatibility among objects. These systems try to solve broader problems than simply being able to replace a DLL with a newer version — problems like being able to call member functions on an object that exists on a separate machine, maybe with a different operating system, and probably compiled with a different compiler. One book I'd recommend for a general understanding of these broader issues is The Essential Distributed Objects Survival Guide [4] . Be warned: the authors express rather strong opinions, and if you're a Microsoft fan you may find this book offensive.
In your case you're looking for something quite a bit simpler. You need to figure out how to ensure that calls to existing objects will continue to work properly when you replace the DLL that implements the member functions of these objects. For most classes this means making sure that you can correctly access three things: non-virtual functions (both members and nonmembers), virtual functions, and member data.
For non-virtual functions, under Windows, you must guarantee that their ordinals are the same in the new DLL. In practice that means using a .DEF file to specify the ordinals for all of the exported functions. I don't know what's needed with Unix shared libraries, but if you're working on a Unix platform with shared libraries you probably know how to do this.
Virtual functions are a bit more tricky. You've probably run into the debugging nightmare that occurs when you add a virtual function to a class and forget to recompile one of the source files that uses that class. The file that you didn't recompile still uses the old vtable layout, and when you step through the code with a debugger you run into function calls that go to the wrong function. That's because the address of the function is stored in the vtable, and the compiler generates code to get this address at run time to call the function. If you've gotten your vtables mixed up the compiler gets the wrong address. The solution in this case, of course, is to recompile the offending source files.
When you're replacing a DLL you can't force your users to recompile all of their code. You must keep the vtable layout the same when you update the implementation of the object. The language definition doesn't say anything about this (in fact, it says nothing about vtables, which are merely an implementation detail). But you've got the right heuristic: if you keep the declarations of the virtual functions in the same order, chances are that your compiler will lay the vtable out in the same way. You should check this with each new build. It's fragile.
Data access is nasty. The simplest solution is probably to keep all your data private and never provide any inline functions to users that access that data. The idea here is to try to ensure that your user's code never deals directly with any of your class's data. Then, as long as you don't change the actual size of the object, you can change the data layout without having to worry about compatibility problems.
Now, that's all a fairly complex set of rules to have to work with, and the result is code that can be quite brittle. A better answer is to provide only an abstract base class for users of your class, one that can be defined once and never changed. In your DLL you implement a class derived from this abstract base class. You are free, in your derived class, to change the implementation in any way you like. You also must provide a "factory method" to create an object of your type, and return a pointer to your abstract base class to your user. Users of your DLL see only the abstract base class, so they won't have to adapt to changes in implementation details. That's the mechanism that COM uses. COM objects are nothing but vtables, and all the implementation details are encapsulated in the DLL. Users simply work with pointers to abstract bases, without concerning themselves how the object is actually implemented.
In practice, your code might look something like this:
// my_class.h class my_class { public: virtual void f1() = 0; virtual void f2() = 0; protected: virtual ~my_class(); friend void destroy_my_class( my_class * ); }; // factory method my_class *create_my_class(); void destroy_my_class( my_class * ); // my_class_imp.h #include "my_class.h" class my_class_imp : public my_class { void f1(); void f2(); private: ~my_class_imp(); int data1; double data2; }; // my_class_imp.cpp #include "my_class_imp.h my_class *create_my_class() { return new my_class_imp; } void destroy_my_class( my_class *cls ) { delete cls; } void my_class_imp::f1() { // implementation goes here } void my_class_imp::f2() { // implementation goes here }When you build your DLL you compile my_class_imp.cpp. When you deliver your DLL to users you provide the DLL, the import library, and my_class.h. You don't give them my_class_imp.h, because its contents are none of their business. Users of your DLL are restricted to using the abstract base class, and won't be affected by changes in your implementation. o
Notes
[1] Okay, you caught me oversimplifying. Yes, if you use placement new to construct an object in your own memory block you don't need to (and can't) use delete on that object.
[2] In almost all situations. This decay does not occur when the name of the array is used as the argument to sizeof, nor does it occur in the declaration of the array.
[3] Incidentally, in an actual program I wouldn't use the name pchararray here. The name should describe the role of this data object in the program, rather than its type. If we're dealing with messages as I've assumed here, I'd probably name it Messages.
[4] Robert Orfali, Dan Harkey, and Jeri Edwards. The Essential Distributed Object Survival Guide (John Wiley & Sons, 1996). ISBN 0-471-12993-3.
Pete Becker is a consultant who specializes in teaching C and C++ to experienced programmers. He spent eight years in the C++ group at Borland international, both as a developer and manager. He is a member of the ANSI/ISO C++ standardization committee. He can be reached by e-mail at petebecker@acm.org.