vstream mode -d dbname options filenameExport the contents of a database to a file or import data from a file into a database.
Basic elements are:
|
|
Import or export the database. |
|
|
Name of database to receive or supply data. |
|
|
Import or export options. |
|
|
Name of file to receive or supply data. |
Mode
|
-i |
Stream data from a file to a database. |
|
-o |
Stream data from a database to a file. |
Input mode,
-i
vstream reads in objects according to the exported data file and creates a new logical object identifier (loid) for each object. The -p option allows you to use the same loid's as in the original database.
-o
vstream iterates through all the objects in the database using cursors and streams the objects to a file. You can use the option -n to set how many objects to read in each cursor fetch. The default setting limits the number of objects read in one cursor fetch to not exceed 80% of the cache size.
Options
options parameter are:
-p
The -p option ensures that logical object identifiers are not changed during the import process.
When importing data from a file to a database in multiple executions of vstream, you must use the -p option to preserve link relationships.
vstream -o -d db -c A data1.dat
vstream -o -d db -c B data2.dat
Then, later, if you import these two database files into a database with the following commands, the link relationships between A and B will not be set properly:
vstream -i -d db data1.dat
vstream -i -d db data2.dat
However, link relationships will be set properly with the following commands, because the logical object identifiers were preserved:
vstream –i –p –d db data1.dat
vstream –i –p –d db data2.dat
When exporting data, if logical object identifiers are to be preserved in a destination database, you should either filter by class name or set level filtering to 1. If level filtering is set to a number greater than 1, some duplication in the data stream might occur.
-t num
The default is one iteration, which means vstream releases memory after each cursor fetch or after reading each vstr from an exported data file.
-n num
-l level
The default is -1, which means read the entire object graph.
Specify a positive number to specify a particular number of levels to export. Setting a low level number, such as 1, will reduce memory requirements.
If you specify the option -1 (read entire graph), vstream will write the morphology data to a file. The name of this file will be the same as your data file, except with the suffix ".morph". This file must be present for vstream to recreate the database.
-g
This option will improve performance if your object graph (the object tree) is not very complex.
-f
This option improves performance but requires a lot of memory.
-sa
The default is to export a database created by VisualWorks.
With only one exception, it does not matter what interface language you used to create objects: the objects you are exporting are interface independent.
However, if you have created objects with the VisualAge Smalltalk interface, you must specify the option –sa when exporting.
-c class
The default is to export the entire database.
If you specify the -c option, vstream will write morphology data to a file. The name of this file will be the same as your data file, except with the suffix ".morph". This file must be present for vstream to recreate the database.
-q query
The query should have the general form "class attribute op value"
where:
attribute is the attribute name,
op is one of {==, <, >, <=, >=, !=}, and
value is the attribute value which must be matched.
Place the query in quotes so that it is parsed as a single argument.
Specifying levels to export
For example, streaming out a database with level 1 will export all the top level objects without following any further links; streaming with level 2 will force vstream to export an object and any object that is linked to it. The internal morphology map will guarantee the consistency of the object graphs.
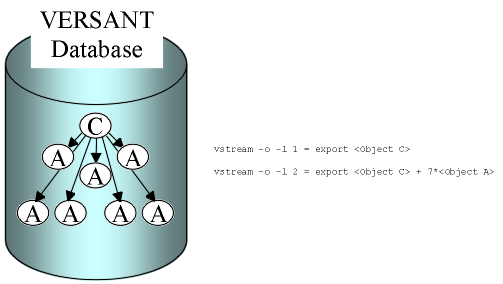
vstream –l execution, all the object relationships (morphology) are preserved.
Synchronizing schema
vstream will try to synchronize the class definitions in the new database.The attributes in the stream schema and the database schema must be equal in name, type, and repetition factor for a successful match. The following schema synchronization rules apply:
• Any object attributes present in the database schema and not present in the stream schema will not be overwritten.
• Any object attributes present in both the database and stream schema is overwritten by the stream value. Attributes do not have to be in the same sequence.
• Any linked attributes present in the stream but not in the database are still processed, but not reproduced. The subgraph of the link is still read in.
• Any non-linked attributes present in the stream but not in the destination database are ignored.
Operating across platforms and releases
vstream across platforms. For example, you can stream out a HP database and then restore it on a Solaris machine.Data can be streamed across different versions of VERSANT. However, when you stream from a newer versioned database to a older versioned database, make sure that you don't have any version-related system class inside your new database that cannot be handled in the old database.
The only limitation on compatibility is the necessity to use the -sa option when exporting objects created with VisualAge Smalltalk.
Estimating operating system resources
vstream.
vstream utility requires adequate random-access memory (RAM) and a swap file of sufficient size to hold the morphology data. You can estimate the operating system (OS) resources needed for the streaming process for a given database size.
vstream probably does not have enough RAM.
Task Manager>Processes>Page Faults; if it changes quickly, little progress is probably being made.
To export when memory is low, you may need to export only top-level objects by using the -l 1 option.
Example — Following is an example that calculates resources based on Windows NT operating system requirements. The same equations are used to generate the resource requirements for a UNIX system.
The first step in estimating resources is to consider the object graph. The complexity of a given database object graph depends on the number of links between objects. In a worst case graph, each object is linked to every other object; in a best case graph, each object is isolated.
The table below lists object graph scenarios and the typical amount of RAM needed according to the number of objects, x, in the graph.
Graph Complexity —
|
Scenario |
RAM |
Swap File |
|
Worst Case |
40x |
40x |
|
Average Case |
20x |
40x |
|
Best Case |
4x |
40x |
The swap file must be large enough to contain the entire morphology map, which is always 40 times the number of database objects.
In the worst case scenario, an average object has links to many other objects. This requires references to object information throughout the morphology map and during the streaming process. To achieve an acceptable level of performance, the required RAM size is approximately 40 times the number of objects plus the amount of RAM needed by the operating system.
In the average and best case scenarios, the object graph is relatively sparse and objects once processed are not referenced again. You still need the same swap file size, but the amount of RAM required is reduced to half or less. You can stream databases with smaller amounts of RAM if a typical object is referenced only a few times. Once these objects are swapped to disk by the operating system, it is less likely that they will be needed again. In the worst case scenario, however, many objects are frequently referenced and the insufficient available RAM can cause page faults.
The following formulas can be used to estimate the amount of operating system resources (RAM and swap file) needed:
Required RAM = (factor * ObjectCount) + OsRAM
Required swap file size = (40 * ObjectCount) + OsSwap
Elements of the above equations are:
|
|
Based on the morphology scenario (see the Graph Complexity table above). |
|
|
The approximate number of database objects. You can calculate number of database object by running the |
|
|
The operating system requirement for RAM. |
|
|
The operating system requirement for the swap file. |
The following examples illustrate this method of estimating operating system resources in two cases. The operating system sizes in the examples refer to Windows NT. The RAM and swap file requirements are similar on other supported platforms.
Example Operating System Resource Requirements—
|
Database size |
400 MB |
1 GB (4) |
|
Object count (1) |
2 million |
10 million |
|
Case |
worst |
Average to Best |
|
Factor |
40 |
15 (5) |
|
RAM (2) |
(40*2*106)+30MB = 110MB |
(15*107)+30 MB = 180MB |
|
Swap file (3) |
(40*2*106)+100MB = 180MB |
(40*107)+100MB = 500MB |
Table Notes:
(1) Can be calculated using db2tty.
(2) Most databases will not require this maximum RAM amount. A test using a highly connected or worst case database of 380MB ran perfectly with a 96MB RAM limit. The Windows NT OS alone requires 30MB. If additional applications are running, increase this value. Vary this value for other operating systems accordingly.
(3) The Windows NT OS alone requires 100MB. Additional running applications will require an increased swap file size. Vary this value for other operating systems accordingly.
(4) With a database of this size, it is likely that the graph is sparse, so the user should consider this an average or best case scenario.
(5) Because this database is large and is between the suggested values for average (20) and best (4) cases, evaluate your database and choose this number.
On Windows NT operating system, the default stack limit is 1MB; on Solaris it is 8M.
For an object graph whose level exceeds 1000, we recommend that you use level filtering.
Usually importing is faster than exporting. It takes about 4.5 hours to stream out a 400 MB database with level 1 filtering and 3 hours to stream it in on a sparc Ultra Server.
vstream utility replaces the previous utilities vimport and vimport. The vstream has additional functionality and better memory usage.